

مدلهای هوش مصنوعی مانند DALL-E و Stable Diffusion اخیراً توانایی خارقالعادهای در ایجاد تصاویر و آثار هنری نشان دادهاند. به آنها یک توضیح متنی مانند “صندلی راحتی به شکل آووکادو” بدهید و آنها می توانند آن صحنه را با جزئیات واضحی ارائه کنند.

اما اگر بخواهیم این مدلها را برای تطابق بهتر با اهداف خاص فراتر از نمایش دقیق درخواستها اصلاح کنیم، چه؟ به عنوان مثال، میخواهیم مدلی را برای تولید تصاویری زیبا و متناسب با تبلیغات رسانههای اجتماعی، با رنگهایی که توجه را جلب میکند، تنظیم کنیم. یا آن را به سمت تولید هنر انتزاعی به جای تصویرسازی تحت اللفظی هدایت کنید؟
تحقیق جدیدی از دانشگاه برکلی به بررسی چگونگی استفاده از reinforcement learning (RL) برای بهینهسازی مدلهای Diffusion به طور مستقیم برای اهداف مشخص شده توسط کاربر فراتر از تولید مجدد دادههای آموزشی میپردازد. با فرمولبندی فرآیند تولید تصویر بهعنوان دنبالهای از تصمیمها، آنها از الگوریتمهای policy gradient برای به حداکثر رساندن پاداشهایی مانند زیبایی تصویر یا مرتبط بودن با پرامپت استفاده میکنند. توانایی هدایت این مدلها بدون تکیه بر دادههای آموزشی لیبل گذاری شده میتواند آنها را حتی بیشتر با نیازهای کاربر تطبیق بدهد.
در این پست، ایدههای کلیدی این مقاله و راه جدیدی که برای آموزش این مدل ها برای اهدافی مانند خلاقیت، زیبایی و مرتبط بودن تصویر ایجاد شده با متن، توسعه داده شده است را بررسی می کنیم. در انتها خواهیم دید که نگاه به این موضوع به عنوان یک مسئله RL، چگونه فرصتهای جدیدی را برای بهبود این هوش مصنوعیهای خلاق بوجود میآورد!
مدل های Diffusion چگونه کار می کنند؟
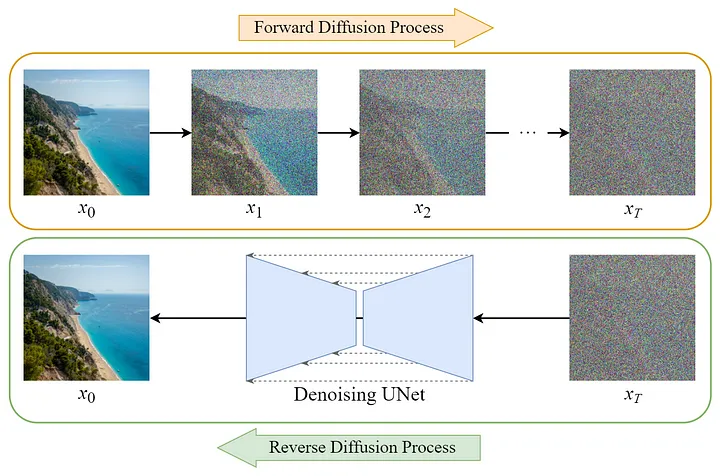
برای درک اینکه چگونه RL می تواند در مدل های Generative اعمال شود، ابتدا باید بدانیم مدل های Diffusion چه هستند و چگونه کار می کنند.
مدلهای Diffusion، یک نوع از مدلهای Generative عمیق هستند که میتوانند دادههای بسیار واقعی مانند تصاویر، صدا و اشکال سهبعدی را ایجاد کنند. ایده اصلی این است که آنها یاد بگیرند که نویز ساده را دریافت کنند و از طریق حذف نویز، به تدریج آن را به داده های پیچیده تر تبدیل کنند.
به طور خاص، یک مدل Diffusion با استفاده از نمونه داده های واقعی مانند تصاویر و اضافه کردن تدریجی نویز برای خراب کردن آنها در چندین مرحله آموزش داده میشود. در هر مرحله، مدل آموزش داده می شود تا داده های خراب را بگیرد و مقداری نویز را حذف کند تا به داده های واقعی و اصلی برگردد. این حذف نویز توسط یک شبکه عصبی انجام میشود که یاد می گیرد چگونه در هر مرحله خرابی نویز را معکوس کند.
پس از آموزش، مدل Diffusion میتواند نمونههای جدیدی را با شروع با نویز خالص از طریق مدل حذف نویز آموخته شده در چندین مرحله تولید کند. گام به گام، شبکه عصبی با یادگیری الگوهایی از تمام داده هایی که در طول آموزش مشاهده می کند، به تدریج نویز را به تصاویر یا صداهای قانع کننده تبدیل می کند.
بنابراین به طور خلاصه، مدلهای Diffusion، توزیعهای ساده را در مراحل کوچک متعدد نویززدایی، که هرکدام کمی نویز را حذف میکنند، به داده دلخواه تبدیل می کنند. نتیجه یک مدل Generative انعطافپذیر است که میتواند خروجیهای واقعی و متنوع را تولید کند.
اکنون که نحوه کار آنها را فهمیدیم، بیایید ببینیم که RL چگونه به ما امکان بهینه کردن این مدل ها برای اهداف جدیدی فراتر از تولید مجدد داده های آموزشی میدهد!
استفاده از RL
روش استاندارد آموزش مدلهای Diffusion بهینهسازی مدل برای بازتولید توزیع دادههای آموزشی است. با این حال، برای بسیاری از کاربردها میخواهیم مدل را برای اهدافی فراتر از این را بهینه کنیم.
این جایی است که RL وارد می شود. بینش کلیدی این است که ما می توانیم فرآیند حذف نویز در مدل های Diffusion را به عنوان یک فرآیند تصمیم گیری مارکوف (MDP) فرموله کنیم. در این صورت هر مرحله از حذف نویز به یک «عمل» تبدیل میشود و میتوانیم «پاداش» را برای ویژگیهایی که میخواهیم بهینه کنیم، مانند زیبایی تصویر یا شباهت به متن داده شده، تعریف کنیم.
با این فرمول ، اکنون می توانیم از تکنیک های RL مانند الگوریتم های policy gradient برای آموزش مدل استفاده کنیم و هدف از بیشینهسازی درستنمایی(likelihood) در دادههای آموزشی، به حداکثر رساندن پاداش تجمعی مورد انتظار در مراحل متعدد حذف نویز تبدیل میشود.
برای مثال، میتوانیم پاداش را برای تصاویری که با توصیف داده شده مطابقت دارند، یا مطابق با یک مدل آموزش داده شده جذابیت بیشتری داشته باشند، بالاتر تنظیم کنیم. همانطور که مدل انتشار برای به حداکثر رساندن پاداش آموزش داده می شود، میآموزد که تصاویری تولید کند که آن ویژگی های مورد نظر را منعکس میکنند.
این امر فرصتهای جدید بسیاری را برای هدایت مدلهای Generative بر اساس پاداشهای منعطف تعریفشده توسط کاربر که اهداف پایین دستی را نشان میدهند، فراهم میکند. آنها میتوانند به جای تقلید داده های آموزشی، بهینه سازی اهداف انتزاعی را که بیانگر خواسته های کاربران است، بیاموزند.
محققان دو نوع الگوریتم policy gradient را برای این MDP مدل Diffusion پیشنهاد میکنند که از آموزش مبتنی بر درستنمایی استاندارد بهتر عمل میکند. در ادامه به بررسی این الگوریتم ها میپردازیم.
روش های پیشنهادی
محققان دو الگوریتم RL را برای آموزش مدلهای Diffusion پیشنهاد میکنند:
- DDPOSF: این روش از الگوریتم REINFORCE، که به عنوان تخمینگر تابع امتیاز نیز شناخته می شود، استفاده میکند. این الگوریتم گرادیانهای لگاریتم درستنمایی را در طول هر مرحله نویززدایی جمعآوری کرده و از آنها برای بهروزرسانی پارامترهای مدل به منظور بیشینه کردن پاداش مورد انتظار استفاده میکند.
- DDPOIS: این رویکرد از نمونه گیری نقاط مهم برای برآورد بهتر گرادیان در مواردی که چندین بهروزرسانی پارامتر در هر دور از جمعآوری دادهها انجام میشود، استفاده میکند. نسبتهای درستنمایی، به حساب آوردن سیاست در حال تغییر حین آموزش را امکانپذیر میسازند.
هر دو روش عملکرد بهتری نسبت به آموزش مبتنی بر درستنمایی با وزندهی پاداش داشتند که محققان آن را RWR مینامند. RWR از تابع loss استاندارد مدلهای Diffusion استفاده میکند اما اجزای آن را بر اساس مقادیر پاداش وزندهی میکند. اما RWR بر یک تابع زیان درستنمایی تقریبی تکیه میکند که این فرایند متوالی را به طور کامل در نظر نمیگیرد. با مدلسازی دقیق نویززدایی به عنوان یک فرایند تصمیمگیری مارکوف، DDPO قادر است پاداش تجمعی مورد انتظار را با استفاده از درستنماییها و گرادیانهای واقعی بهینهسازی کند.
روشهای پیشنهادی، RL را برای مدلسازی Generative با ارائه الگوریتمهای عملی برای بهینهسازی پاداشهای انتزاعی فراتر از صرف درستنمایی دادهها ممکن میکنند. اکنون بیایید تا به بررسی آزمایش های انجام شده بپردازیم.
آزمایش ها و نتایج

محققان DDPO را با RWR در چند وظیفه تصویرسازی از متن با استفاده از مدل Stable Diffusion مقایسه کردند:
- فشردهسازی: بیشینه یا کمینهسازی اندازه فایل تصویر JPEG با حذف یا افزودن پیچیدگی بصری. DDPO توانست این اهداف را به طور قابل اعتمادی بدون وجود راهنمایی های متنی بهینهسازی کند.
- زیبایی: با بیشینهسازی امتیازات پیشبینی شده از یک مدل ارزیابی خودکار برای امتیاز دهی به زیبایی تصویر، DDPO تصاویری هنرمندانهتر و سبکدار تولید کرد.
- مرتبط بودن متن و تصویر: بیشینهسازی شباهت بین تصاویر و متن با استفاده از درجهبندی خودکار از یک مدل دیداری-زبانی. DDPO تطابق درخواست را بدون نیاز به برچسبهای انسانی بهبود داد.
یافتههای کلیدی عبارتند از:
- DDPO (به ویژه رویکرد نمونه گیری نقاط مهم) به طور مداوم عملکرد بهتری نسبت به RWR داشت که نشاندهنده مزیت روشهای واقعی policy gradient است.
- استفاده از مدلهای دیداری-زبانی برای محاسبه پاداش امکان آموزش تطبیق تصاویر با متن را بدون نیاز به امتیازدهی پرهزینه انسانی فراهم کرد.
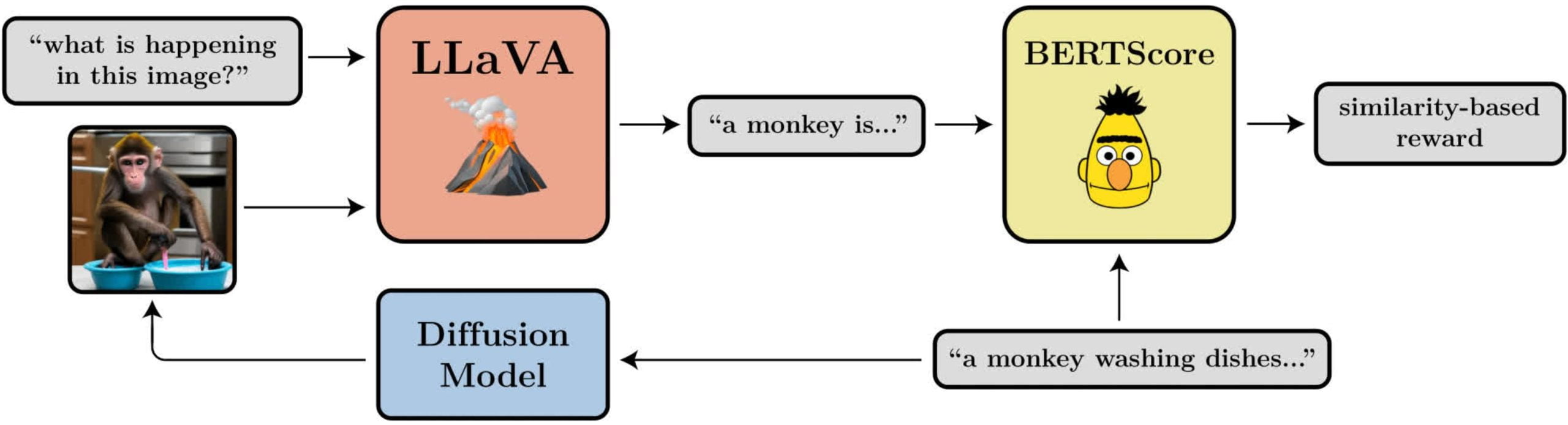
- بهبودها فراتر از متن های موجود در داده های آموزشی تعمیم یافت و مدل را به طور گستردهتری تطبیق داد.
این آزمایشها در مجموع نشان میدهند که DDPO امکانات جدیدی را برای هدایت مدلهای Generative به سمت اهداف مشخصشده توسط کاربر، فراتر از صرف مدلسازی دادههای آموزشی فراهم میکند. استفاده از پاداشهای خودکار، مانع محدودیت داده که ممکن است در غیر این صورت کاربرد را محدود کند، بر میدارد.
البته چالشهایی مانند سواستفاده از تابع پاداش و مقیاسپذیری به مدلهای بزرگتر به عنوان سؤالات باز برای مطالعات آینده باقی میمانند. در مجموع DDPO یک پارادایم امیدوارکننده جدید برای آموزش مدلهای Generative هوش مصنوعی منطبق با ترجیحات انسانی ارائه میدهد.
پیادهسازیهای موجود
در حال حاضر دو ریپازیتوری از DDPO موجود است:
- پیاده سازی اصلی مطالعه: این کد بیس تنها روی TPU تست شده و از GPU پشتیبانی نمی کند.
- پیاده سازی برپایه pytorch: این پیاده سازی DDPO، استفاده از GPU و LoRA را ممکن میکند.
- پیاده سازی کتابخانه trl: ساده ترین شیوه موجود برای استفاده از DDPO به شمار می رود.
به طور خلاصه، پیادهسازی دوم به دلیل پشتیبانی از LoRA که نیاز به مموری کمتری دارد، بهترین جا برای آشنایی بیشتر با این روش است.
جمع بندی
این مقاله یک کاربرد جالب از RL را برای آموزش مدلهای Generative به طور مستقیم بر روی پاداشهای مشخص شده توسط کاربر که اهداف پایین دستی را نشان میدهند، ارائه کرد.
با فرمولبندی فرآیند حذف نویز در مدلهای Diffusion بهعنوان یک فرآیند تصمیمگیری مارکوف، محققان یک رویکرد policy gradient را برای بهینهسازی اهداف انتزاعی فراتر از درستنمایی دادهها معرفی کردند.
آزمایشها نشان داد که الگوریتمهای DDPO پیشنهادی میتوانند معیارهایی مانند زیبایی و ارتباط متن و تصویر را بهتر از آموزش بیشینه کردن درستنمایی استاندارد بهبود بخشند.
به طور اساسی، استفاده از مدلهای دیداری-زبانی برای محاسبه پاداش، نیاز به تلاشهای اضافی برچسبگذاری انسانی را که ممکن است کاربرد را محدود کند، از بین میبرد.
در حالی که چالشهای پیرامون مقیاسپذیری و بهینهسازی افراطی پاداشها همچنان وجود دارد، این کار یک الگوی جدید امیدوارکننده برای آموزش مدلهای Generative ارائه میدهد که با ترجیحات انسانی همسو هستند.
هدایت مدلهایی مانند DALL-E و Stable Diffusion به سمت نتایج قابل کنترلتر و سفارشیتر با استفاده از DDPO میتواند درهای بسیاری را برای بهرهبرداری از این فناوریهای جدید و قدرتمند باز کند.
توانایی بهینهسازی مستقیم برای پاداشهای مشخص شده توسط انسان، فصل جدیدی در هوش مصنوعی را نشان میدهد که نه تنها دادهها، بلکه کاربران را در بر میگیرد. تحقیقات بیشتر برای پرداختن به چالش های اشاره شده درباره این رویکرد، قدم هایی کلیدی در مسیر شناخت و بهرهوری بیشتر این مدل ها خواهد بود.
on ChatGPT اما برای تصاویر: تقویت مدل های Diffusion با DDPO