

مدلهای دنبالهای (sequence model)، جزئی اساسی در بسیاری از سیستمهای یادگیری ماشین مدرن هستند، به ویژه مدلهای بنیادی بزرگ (FM) که پیشرفتهای اخیر در هوش مصنوعی را برانگیختهاند. مدلهای بنیادی بر روی مجموعههای دادهی عظیم آموزش دیده میشوند (pretrain) و سپس برای وظایف پائیندست در مودالیتههای مختلف نظیر زبان، صوت و ژنومیکس (Genomics) تطبیق داده میشوند.
ساختار اصلی برای مدلسازی دنباله در مدلهای بنیادی، معماری ترانسفورمر (Transformer) است. با این حال، ترانسفورمرها نقاط ضعفی کلیدی دارند: افزایش مقیاس درجه دومی (quadratic scaling) آنها محدودیتهایی برای اندازه context که میتوانند مدل کنند ایجاد میکند و هزینه محاسباتی آنها استفاده را محدود میکند. بنابراین محققان به معماریهای کارآمدتر بسیار علاقهمند شدهاند.
متأسفانه، اکثر تلاشهای قبلی نظیر Attention، Performers خطی یا مدلهای state space، در رسیدن به کیفیت مدلسازی ترانسفورمرها ناموفق بودهاند. این مدلهای کارآمد فاقد مکانیزمهایی برای استدلال وابسته به context در مودالیتههای متراکم مانند زبان طبیعی هستند.
Mamba، که در مقالهای از CMU و پرینستون معرفی شده، در پی تغییر این وضعیت است. این مدل معماری جدیدی را بر اساس مدلهای Selective State Spaces (SSMs) ارائه میدهد که از قدرت مدلسازی ترانسفورمرها به همراه افزایش مقیاس خطی (linear scaling) برخوردار است.
نوآوری کلیدی، فراهم کردن امکان انتقال اطلاعات به صورت انتخابی (Selective) در ابعاد دنباله توسط SSMها است. این مکانیزم “انتخاب” آگاهانه به Mamba کیفیتی در حد ترانسفورمرها در مدلسازی زبان و دامنههای دیگر را میدهد در حالی که ۵ برابر سریعتر است.
در این پست، ما چگونگی کار Mamba را توضیح خواهیم داد، شواهد تجربی برای کیفیت مدلسازی و کارآمدی آن را ارائه خواهیم کرد و توانایی آن را به عنوان یک معماری کارآمد برای مدلهای بنیادی بحث خواهیم نمود.
مشکل مدل های موجود
مدل غالب در مدلهای بنیادی مدرن، معماری ترانسفورمر است. ترانسفورمرها، مدلهایی نظیر GPT-4 و PaLM-2 را که آخرین دستاوردها را در زمینهی NLP به پیش بردهاند، پشتیبانی میکنند.
با این حال، ترانسفورمرها دو ضعف بنیادین دارند:
- مکانیزم Attention کامل آنها نسبت طول دنباله به صورت درجه دومی افزایش مقیاس مییابد که مدلسازی دنبالههای بسیار طولانی را غیرممکن میسازد.
- هزینه محاسباتی و حافظه مورد نیاز آنها باعث میشود پیادهسازی این مدلها پرهزینه باشد.
انواع مختلف و کارآمد ترانسفورمر مانند Performers، Linformer، و Random Feature Attention پیشنهاد شدهاند. اما در اصل، این ترانسفورمرهای خطی، به خاطر کارآمدی، کیفیت مدلسازی را فدا میکنند. بدون Attention کامل، آنها نمیتوانند با ترانسفورمرها در مودالیتههای متراکم نظیر زبان طبیعی رقابت کنند.
معماریهای دیگری که امیدبخش هستند عبارتند از Attention خطی، که از recurrence سریع بین stateها استفاده میکند و مدلهای structured state space (SSM) که از نظریه کنترل الهام گرفته شدهاند. با این حال، هر دو فاقد انتخابگری (Selectivity) هستند (توانایی انتقال یا فراموشکردن اطلاعات به صورت آگاهانه). آنها در دادههای گسسته مانند متن یا DNA در مقایسه با دادههای پیوسته مانند صوت، اثربخشی محدودی دارند.
مدلهای کارآمد قبلی در این معامله بین کارآمدی و تراکم مدلسازی گیر کردهاند. هدف، یافتن راهکاری برای حفظ توانایی برهمکنش context به اندازه Attention کامل است، در حالی که پیچیدگی محاسباتی را به خطی کاهش میدهد.
Mamba نوآوریهایی را برای Selective کردن مدلهای state space معرفی میکند، و در نهایت مدلی را ارائه میدهد که میتواند به کیفیت ترانسفورمرها نزدیک شود، در حالی که در عمل تا ۵ برابر سریعتر است.
معرفی Mamba
نوآوری کلیدی Mamba این است که به مدلهای state space (SSMs) اجازه میدهد تا استدلال انتخابی (Selective) را در ابعاد دنباله انجام دهند. این کار را از طریق دو مکانیزم اصلی انجام میدهد:
- مکانیزم انتخاب: Mamba پارامترهای SSM را وابسته به ورودی در هر timestep میکند. برای مثال، ماتریس انتقال A به تابع A(x) که بر اساس ورودی فعلی x تغییر میکند، تبدیل میشود. این مسئله اجازه میدهد تا مدل به صورت انتخابی اطلاعات را در state مخفی h منتشر کند یا فراموش کند.
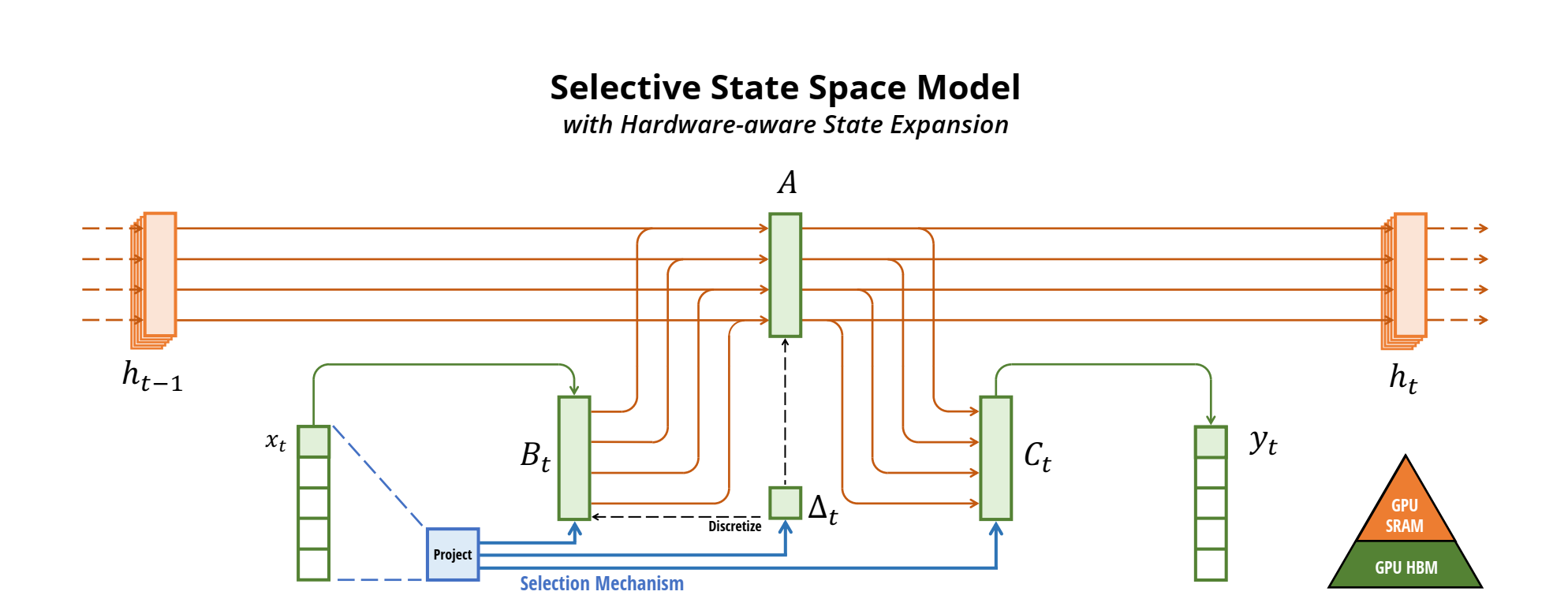
- الگوریتم آگاه از سختافزار: محاسبه SSMهای وابسته به ورودی در حالت عادی بسیار گران خواهد بود. Mamba از تکنیکهایی مانند kernel fusion و parallel scan که برای پردازشگرهای گرافیکی (GPU) سفارشی شدهاند، استفاده میکند تا از materialize کردن state کامل جلوگیری کند.
با هم، این مکانیزمها به Mamba اجازه میدهند تا tokenهای غیر مرتبط را حذف کرده و هنگام پردازش دنبالههایی با طول متغیر، روی محتوای مرتبط تمرکز کند. این انتخاب، مدلسازی context با کیفیت ترانسفورمر را در حالی که پیچیدگی محاسباتی خطی حفظ شده است، فراهم میآورد.
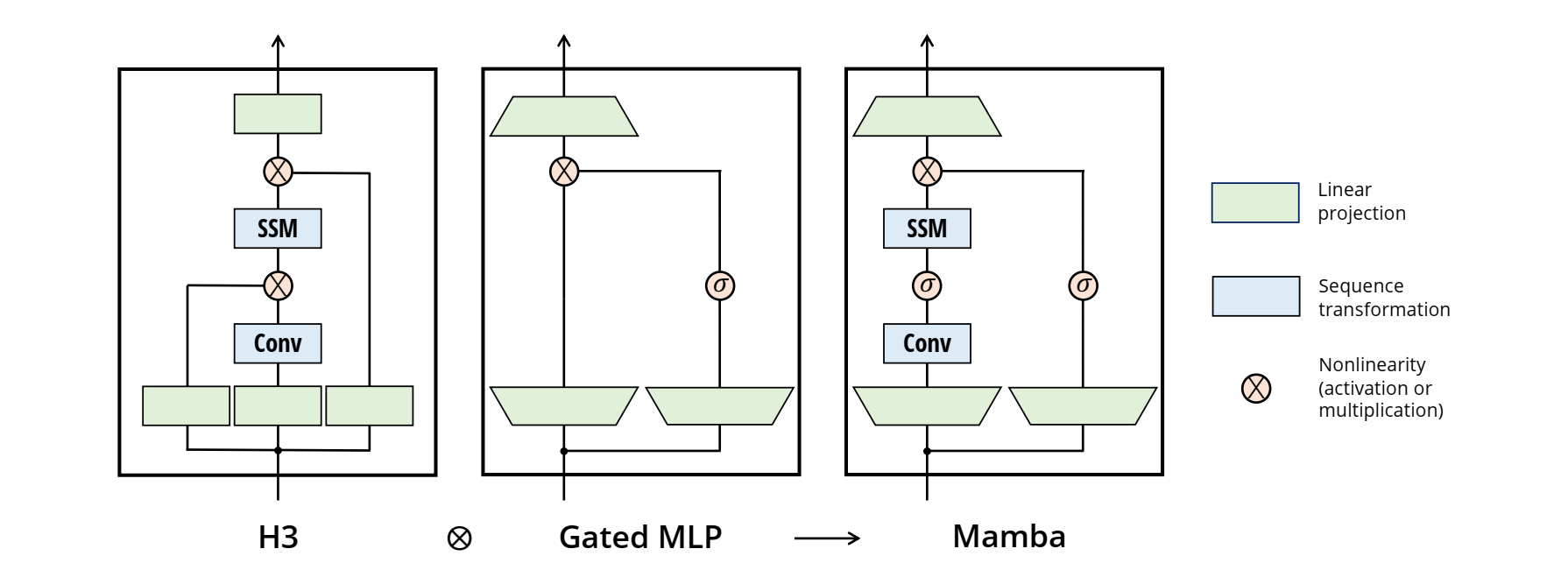
علاوه بر این، Mamba معماری کلی را ساده میکند. جایی که مدلهای SSM قبلی یک لایه SSM را با یک لایه MLP درهم میآمیختند، Mamba هر دو عملکرد را در یک بلوک منفرد ترکیب میکند. قرار دادن این بلوک همگن، مدلهایی را که از نظر مفهومی سادهتر هستند ایجاد میکند.
به صورت ملموس، Mamba مکانیزم Attention که در ترانسفورمرها استفاده میشود را جایگزین میکند. بدون Mamba ،Attention همچنین از گلوگاه (bottleneck) حافظه برای contextهای طولانی در زمان inference پرهیز میکند. این اجازه میدهد تا مدلهای Mamba قابلیت پردازش بسیار بالاتری را تحقق بخشند.
نتایج مقایسهها
توانایی Mamba به طور گستردهای در مودالیتههای مختلف سنجیده شد و نتایجی را نشان داد، که ترانسفورمرها و مدلهای قبلی کارآمد را پشت سر گذاشت.
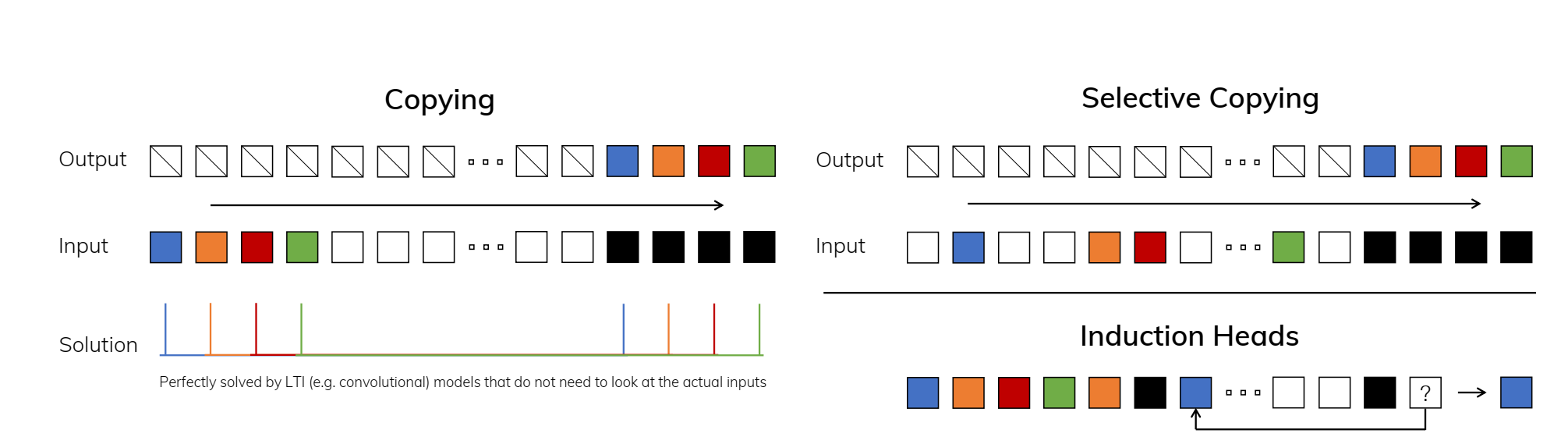
در وظایف ساختگی، Mamba چالشهایی مانند selective copying و induction heads که به استدلال انتخابی نیاز دارند را حل کرد. این مدل راه حلهایی را به دنبالههایی که نسبت به چیزی که در طول آموزش دیده بود بسیار طولانی تر بودند، استنتاج کرد.
برای مدلسازی زبان، Mamba نزدیک به یک دستورالعمل آموزش ترانسفورمر بهینه شده (“ترانسفورمر++”) در اندازههای مدلی تا ۱.۳ میلیارد پارامتر عمل کرد. Mamba اولین مدل subquadratic بود که مدلسازی زبانی باکیفیت ترانسفورمر را به دست آورد. Mamba در contextهای تا ۱ میلیون token هنگام پیشآموزش بهبود یافت. این مدل بیش از ۵ برابر نسبت به ترانسفورمرها بهینه تر بود و جدیدترین دستاوردها را در وظایف زبانی پاییندست معمول به دست آورد.
در ژنومیکس، Mamba بر مدلهایی مانند HyenaDNA در پیشآموزش روی ژنوم انسان برتری داشت. این مدل برخلاف مدلهای قبلی با contextهای طولانیتر تا ۱ میلیون جفت باز (base pair) بهبود یافت. پس از پیشآموزش، دقت بالاتری را در وظیفه چالشبرانگیز دستهبندی گونهها که به استدلال long-range نیاز دارد، دست یافت.
برای موج صوتی، یک مدل کوچک Mamba در بنچمارک تولید صدا نسبت به GAN برتری داشت. در مدلسازی contextهای صوتی نیز بار دیگر از مدلهای قبلی پیشی گرفت.
در مجموع، در مودالیتهها، وظایف و اندازههای مدل، Mamba به طور مداوم با ترانسفورمرها برابری کرد یا از آنها پیشی گرفت در حالی که از حافظه و محاسبه کمتری استفاده میکرد. افزایش خطی آن اجازه استفاده از context طولانیتری نسبت به آنچه ترانسفورمرها میتوانند اداره کنند، را میدهد. به عنوان اولین مدل کارآمد که به کیفیت رقابتی دست یافت، Mamba به عنوان یک ساختار اصلی مدلسازی دنباله کلی برای مدلهای بنیادی آینده امیدوار کننده است.
1 دیدگاه on سریعتر و قدرتمندتر: معرفی معماری Mamba
جالب بود