

در قلمرو مدلهای زبانی، تلاشهای اخیر عمدتاً به نفع چند زبان منتخب غنی از داده بوده و بسیاری دیگر از زبانها در نظر گرفته نشده اند. با این حال، تلاش برای گسترش مزایای این پیشرفتها به یک طیف زبانی گستردهتر ادامه دارد. Aya با هدف حل همین مشکل توسعه داده میشود.
Aya فقط یک مدل زبانی دیگر نیست. این یک مدل مولد چند زبانه است که قادر به درک و اجرای دستورالعمل ها در 101 زبان است. چیزی که Aya را متمایز می کند، تعهد آن به فراگیری است. بیش از 50 درصد از این زبان ها به عنوان منابع پایین دسته بندی می شوند. Aya از پیشینیان خود، mT0 و BLOOMZ، در بسیاری از وظایف برتری دارد و در عین حال تعداد زبان های تحت پوشش را دو برابر می کند.
اما تأثیر Aya از معیارهای عملکرد فراتر می رود. این مدل پیشگام مرز جدیدی در ارزیابی چند زبانه است و مجموعههای ارزیابی جامعی را معرفی میکند که شامل وظایف مولد، ارزیابیهای انسانی و نرخهای برنده شبیهسازی شده در ۹۹ زبان است. این ارزیابیها نه تنها مرزهای هوش مصنوعی چندزبانه را پیش میبرد، بلکه جنبههای مهمی مانند toxicity، سوگیری و ایمنی در مدل را نیز روشن میکنند.
سازندگان Aya مجموعه دادههای دستورالعمل خود و خود مدل را به صورت متنباز منتشر کردهاند و از محققان و علاقهمندان به کشف قابلیتهای آن و کمک به تکامل آن دعوت میکنند. این تعهد به شفافیت و دسترسی بر نقش Aya به عنوان یک کاتالیزور برای پیشرفتهای دموکراتیک در پردازش زبان طبیعی تأکید میکند.
به ما بپیوندید تا به پیچیدگی های Aya بپردازیم – گواهی بر قدرت تنوع زبانی و پتانسیل بی حد و حصر هوش مصنوعی چند زبانه
مقابله با عدم تعادل داده های چند زبانه
The limits of my language means the limits of my world. — Ludwig Wittgenstein
در یادگیری ماشین، در بر گرفتن تنوع زبانها و مفاهیم یک چالش مهم است. مجموعه دادههای موجود، که برای آموزش مدلها بسیار مهم هستند، به شدت از چند زبان غنی از داده استفاده میکنند و غنای زبانی دنیای واقعی را نادیده میگیرند. این روند به پیشرفتهای اخیر در پردازش زبان طبیعی (NLP) گسترش یافته است، جایی که مدلهایی مانند Alpaca و Vicuna در درجه اول به وظایف انگلیسی پاسخ میدهند.
Instruction finetuning (IFT) نویدبخش بهبود عملکرد مدل است، اما تفاوت فاحشی در در دسترس بودن دستور العمل ها بین انگلیسی و سایر زبان ها وجود دارد. این عدم تعادل نه تنها اصول اساسی یادگیری ماشین را نقض می کند، بلکه باعث تشدید سوگیری ها و نگرانی های امنیتی می شود و شکاف دیجیتال را افزایش می دهد.
تمرکز Aya در رسیدگی به این عدم تعادل دادههای چند زبانه و توانمندسازی مدلهایی با قابلیتهای چندزبانه دستورالعملها است. این چالش بر نیاز به مجموعه دادههای چندزبانه جامع تأکید میکند، گامی حیاتی در جهت پر کردن شکاف زبانی در یادگیری ماشین.
اهداف Aya
ماموریت مدل Aya مقابله با محدودیتهای کلیدی در مدلهای چندزبانه تنظیمشده با IFT است، با هدف:
- بهبود عملکرد در میان زبانها: هدف این است که مدل Aya در وظایف مختلف بدون نیاز به Promptهای منحصراً به زبان انگلیسی برتری یابد و فراگیر بودن را ارتقا دهد.
- گسترش پوشش زبان: برخلاف مدلهای موجود با پوشش زبانی محدود، Aya در تلاش است تا از 101 زبان پشتیبانی کند و از بازنمایی زبانی گستردهتر اطمینان حاصل کند.
- گسترش مجموعه داده های آموزشی و ارزیابی: Aya متعهد است که مجموعه دادههای آموزشی و مجموعههای ارزیابی را برای ارزیابی جامع عملکرد Aya در زبان ها و وظایف مختلف گسترش دهد.
مدل Aya نشان دهنده تعهد جامعه هوش مصنوعی به بازنمایی زبانی و فراگیری با هدف تغییر چشم انداز پردازش زبان طبیعی برای آیندهای عادلانه تر است.
افزایش کیفیت داده های چند زبانه
چندزبانگی در مدلهای زبانی بزرگ مدتهاست که با دو چالش اصلی دست و پنجه نرم میکند: کمبود داده و کیفیت پایین داده.
مجموعه دادههای موجود، مانند xP3 و Flan، در حالی که دادههای چندزبانه را در خود جای دادهاند، عمدتاً دستورالعملهایی به زبان انگلیسی دارند. علاوه بر این، این مجموعه دادهها به دلیل اتکا به الگوهای تنظیمشده دستی، که عملکرد مدل را مختل میکند، اغلب از تنوع کم داده رنج میبرند.
برای رسیدگی به کمبود داده های آموزشی چند زبانه، یک رویکرد چند وجهی را برای تقویت در دسترس بودن داده ها اتخاذ شده است. این رویکرد شامل:
- جمعآوری و هرس الگوهای چند زبانه: تلاشهای گستردهای را برای جمعآوری و اصلاح الگوهای چند زبانه انجام شده است که از طیف متنوعی از داده اطمینان میدهد. علاوه بر این، از علامت گذاریهای انسانی، ارائه شده توسط گویندگان مسلط به زبانهای مختلف برای غنیسازی مجموعه داده استفاده میشود.
- استراتژیهای افزایش داده: برای تقویت بیشتر مجموعه داده، از تکنیکهایی مانند ترجمه ماشینی و تولید داده مصنوعی همراه با ترجمه استفاده شده است. این استراتژی ها به افزایش تنوع و غنای داده های آموزشی کمک می کند و عملکرد مدل را بهبود می بخشد.
کمبود مدلهای پایه چندزبانه از پیش آموزشدیده منبع باز جایگزین، پیشرفت آهسته در توسعه چند زبانه را نشان میدهد. با تشخیص وابستگی متقابل بین عملکرد نهایی IFT و کیفیت مدل پایه از پیش آموزش دیده، مجموعه داده Aya را منتشر می شود. با 513 میلیون نمونه چندزبانه، این نسخه بزرگترین مجموعه IFT چندزبانه منبع باز را تا به امروز نشان می دهد، و به محققان این امکان را می دهد تا با مدل های از پیش آموزش دیده پایه مختلف آزمایش کنند.
با افزایش کیفیت و تنوع دادههای چندزبانه، هدف Aya غلبه بر چالشهای IFT است و راه را برای قابلیتهای پردازش زبان طبیعی قویتر و فراگیرتر هموار میکند.
ارزیابی عملکرد Aya
تیم تحقیقاتی توسعه دهنده Aya گامهای مهمی در بهبود عملکرد برای زبانهای محروم برداشته است و قابلیتهای برتر را در طیفی از وظایف پیچیده از جمله درک زبان طبیعی، خلاصهسازی و ترجمه به نمایش گذاشته است.
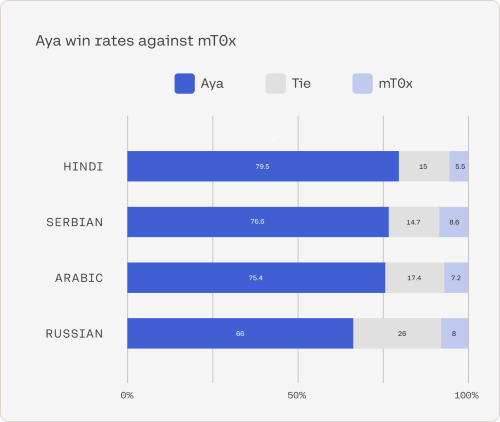
برای ارزیابی عملکرد Aya، این تیم آن را با مدلهای چندزبانه منبع باز موجود مقایسه کرده است. Aya با اختلاف قابل توجهی در تستهای بنچمارک از بهترین مدلهای منبع باز از جمله mT0 و Bloomz بهتر عمل کرد. در ارزیابی های انسانی، Aya به طور مداوم 75 درصد را در برابر سایر مدل های منبع باز پیشرو کسب کرد. علاوه بر این، نرخ پیروزی شبیه سازی شده قابل توجهی از 80٪ تا 90٪ در وظایف مختلف داشت.
یکی از ویژگی های برجسته Aya، پوشش زبانی گسترده آن است، که شامل بیش از 50 زبان مانند سومالی، ازبکی و غیره است. در حالی که مدلهای پیشین در ارائه زبانهای رایج برتری دارند، Aya با ارائه یک مدل متنباز بیسابقه برای دهها زبانی که کمتر مورد توجه قرار گرفته اند، شکاف مهمی را پر میکند.
به طور خلاصه، عملکرد استثنایی، پوشش زبانی گسترده و ماهیت منبع باز Aya، آن را به یک دارایی ارزشمند برای پیشبرد تحقیقات و تقویت فراگیری در زمینه پردازش زبان طبیعی تبدیل کرده است.
جمع بندی
ظهور Aya بر اهمیت حیاتی چند زبانگی در پردازش زبان طبیعی تاکید می کند. Aya با گسترش پوشش زبان و بهبود عملکرد برای زبانهای محروم، شکافهای زبانی را پر میکند و فراگیری را تقویت میکند.
فراتر از دسترسی، چند زبانه بودن درک ما را از تفاوت های ظریف زبان و تنوع فرهنگی غنی می کند. ماهیت منبع باز Aya باعث افزایش شفافیت و همکاری می شود و محققان را برای کشف کاربردهای جدید و توسعه راه حل های بومی توانمند می کند.
با استقبال از چندزبانگی، Aya راه را برای آینده ای فراگیرتر و عادلانه تر در فناوری زبان هموار می کند و با اولویت دادن به تنوع زبانی، فرصت های جدیدی را برای نوآوری و پیشرفت جمعی در سراسر مرزهای زبانی باز می کند.
on Aya: تلاشی در جهت چندزبانگی مدلهای زبانی